在现代数据驱动的开发环境中,高效地从互联网中提取和处理文本数据是一项关键技能。GPT-Crawler作为一款结合自然语言处理技术的文本采集工具,能够自动化完成网页内容提取、语义分析和数据整理等任务。本文将详细介绍GPT-Crawler的核心功能及其使用方法,帮助您更好地理解和掌握这一工具。

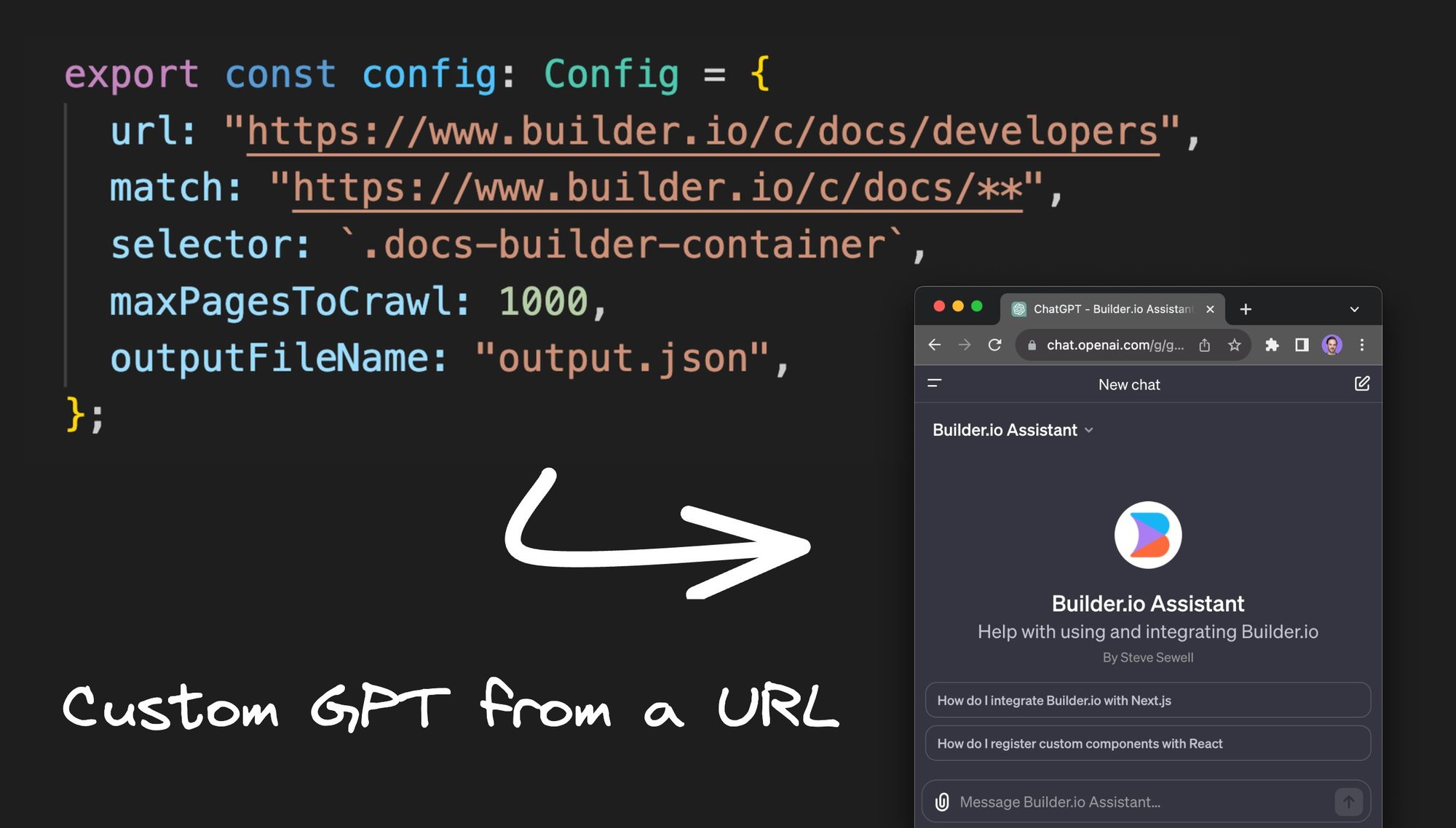
GPT-Crawler简介
GPT-Crawler是一款专注于文本采集与处理的智能工具,通过结合先进的自然语言处理技术和爬虫技术,实现了对网页内容的高效提取和智能分析。它不仅支持多种数据源的采集,还提供了强大的语义理解和结构化处理能力。
核心特性
- 智能文本提取:基于深度学习模型,自动识别并提取网页中的关键文本内容。
- 多源数据支持:支持从HTML、JSON、XML等多种格式的数据源中提取信息。
- 语义分析:利用自然语言处理技术,对提取的文本进行语义分析和分类。
- 灵活配置:允许开发者自定义采集规则和处理逻辑,满足个性化需求。
- 高性能运行:优化的并发处理机制,确保大规模数据采集时的高效运行。
安装与配置
为了开始使用GPT-Crawler,首先需要完成其安装与基础配置。
环境准备
确保您的环境中已安装以下依赖:
- Python 3.7 或更高版本
- 必要的Python库(如requests、BeautifulSoup等)
安装步骤
-
使用pip安装GPT-Crawler:
pip install gpt-crawler -
引入GPT-Crawler到项目中:
from gpt_crawler import GPTCrawler
上述命令会完成GPT-Crawler的基本安装和导入。
使用指南
GPT-Crawler的操作非常直观,只需定义采集目标并启动系统即可完成文本提取和处理。
目标定义
以下代码展示了如何定义一个简单的采集目标:
from gpt_crawler import GPTCrawler
# 初始化GPT-Crawler
crawler = GPTCrawler()
# 定义采集目标
url = "https://example.com"
crawler.set_target(url)
上述代码会创建一个以指定URL为目标的文本采集器。
文本提取
GPT-Crawler会根据设定的目标自动提取网页中的文本内容。例如:
text = crawler.extract_text()
print(text)
上述代码会输出从目标网页中提取的文本内容。
语义分析
GPT-Crawler支持对提取的文本进行语义分析,生成结构化的数据。例如:
analysis = crawler.analyze_text(text)
print(analysis)
上述代码会对提取的文本进行语义分析,并返回分类结果或其他相关信息。
数据导出
GPT-Crawler支持将处理后的数据导出为多种格式,便于后续使用。例如:
crawler.export_data("output.json", format="json")
上述代码会将处理后的数据保存为JSON文件。
高级功能
除了基本的文本采集和处理功能外,GPT-Crawler还提供了许多高级功能以满足复杂场景下的需求。
多源采集
GPT-Crawler支持同时从多个数据源采集信息,实现更全面的数据覆盖。例如:
urls = ["https://example.com/page1", "https://example.com/page2"]
crawler.set_targets(urls)
上述代码会为每个URL分别启动采集任务。
自定义规则
GPT-Crawler允许开发者定义自定义的采集规则,实现更精确的数据提取。例如:
def custom_rule(html):
# 自定义逻辑
return html.find_all("div", class_="content")
crawler.set_extraction_rule(custom_rule)
上述代码会替换默认的文本提取规则为自定义逻辑。
并发处理
GPT-Crawler支持多线程并发处理,显著提升大规模数据采集的效率。例如:
crawler.enable_concurrent_processing(num_threads=4)
上述代码会启用4个线程进行并发数据采集。
数据清洗
GPT-Crawler内置了强大的数据清洗功能,自动去除噪声数据并保留有效信息。例如:
cleaned_data = crawler.clean_data(raw_data)
print(cleaned_data)
上述代码会对原始数据进行清洗,并返回清理后的结果。
总结
GPT-Crawler作为一款智能文本采集与处理工具,以其高效的数据提取能力和强大的语义分析功能赢得了广泛的认可。无论是简单的单页采集还是复杂的多源整合,GPT-Crawler都能提供高效的解决方案。
