在现代信息处理中,光学字符识别(OCR)技术扮演着至关重要的角色。无论是从纸质文档中提取文本,还是对图像中的文字进行识别,OCR都能显著提高工作效率和准确性。EasyOCR是一款基于Python开发的开源OCR工具,它不仅支持多种语言和字体,还具备简单易用的API接口,使得开发者可以快速集成到自己的项目中。
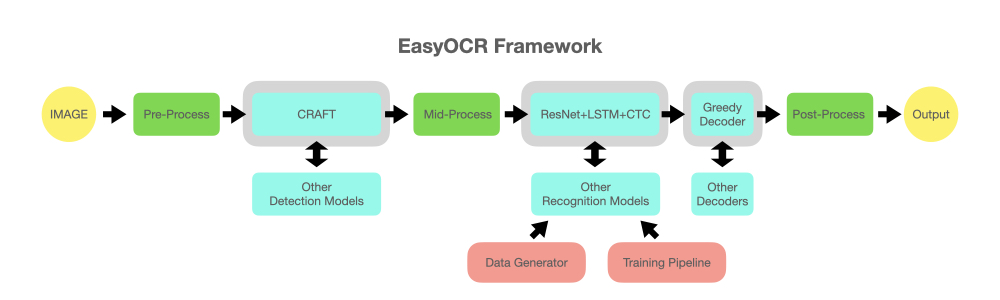
一、初识EasyOCR
1.1 什么是EasyOCR?
EasyOCR是由Jaided AI团队开发的一款高性能OCR库,旨在简化光学字符识别的过程。它基于深度学习模型,并结合了先进的图像处理算法,能够在多种场景下准确地识别文本内容。相比于其他同类工具,EasyOCR具有以下优势:
- 多语言支持:内置了超过80种语言的支持,涵盖了全球主要语言。
- 高精度识别:采用了最新的深度学习模型,确保了较高的识别准确率。
- 易于使用:提供了简洁直观的API接口,无需复杂的配置即可上手。
- 轻量级部署:依赖项较少,安装和运行速度快,适合各种环境。
1.2 核心特性
以下是EasyOCR的主要特性:
- 多语言识别:支持超过80种语言的文字识别,包括中文、英文、日文、韩文等。
- 图像预处理:自动调整图像亮度、对比度等参数,提升识别效果。
- 批量处理:能够一次性处理多个图像文件,提高效率。
- 自定义模型:允许用户训练自己的OCR模型,以适应特定应用场景。
- 跨平台兼容性:适用于Windows、Linux和macOS操作系统。
二、安装与配置
2.1 系统要求
EasyOCR适用于主流的操作系统和硬件环境,具体要求如下:
- 操作系统:Windows、Linux或macOS
- Python版本:3.6及以上
- 内存:建议至少4GB以上
- 硬盘空间:至少500MB可用空间
2.2 安装步骤
2.2.1 使用pip安装
对于大多数用户而言,使用pip是最简单快捷的方式。首先确保已经安装了最新版本的Python,并执行以下命令安装EasyOCR:
pip install easyocr
2.2.2 手动安装
如果不想使用pip,也可以手动安装。首先克隆EasyOCR的GitHub仓库:
git clone https://github.com/JaidedAI/EasyOCR.git
cd EasyOCR
然后安装所需的依赖项:
pip install -r requirements.txt
最后将EasyOCR添加到Python路径中:
python setup.py install
2.3 配置环境
完成安装后,确保所有依赖项都已正确加载。可以通过以下命令验证安装是否成功:
import easyocr
print(easyocr.__version__)
如果输出了版本号,则表示安装成功。
三、常用操作与技巧
3.1 基本用法
EasyOCR提供了非常简单的API接口,只需几行代码即可完成基本的OCR任务。以下是一个简单的示例:
import easyocr
# 创建一个EasyOCR实例
reader = easyocr.Reader(['en'])
# 读取图像文件并进行OCR识别
result = reader.readtext('image_path.jpg')
# 输出识别结果
for (bbox, text, prob) in result:
print(f"识别到的文本: {text}, 置信度: {prob}")
3.2 多语言识别
EasyOCR支持多种语言的混合识别。例如,如果您需要同时识别中文和英文,可以在创建Reader对象时指定这两种语言:
reader = easyocr.Reader(['ch_sim', 'en'])
这样,EasyOCR会自动选择最适合的语言模型来进行识别。
3.3 图像预处理
为了提高识别精度,EasyOCR提供了一些图像预处理的功能。例如,您可以调整图像的大小、旋转角度或应用滤镜来改善识别效果:
from PIL import Image
import numpy as np
# 打开图像文件
image = Image.open('image_path.jpg')
# 调整图像大小
new_size = (800, 600)
image_resized = image.resize(new_size)
# 将PIL图像转换为NumPy数组
image_np = np.array(image_resized)
# 进行OCR识别
result = reader.readtext(image_np)
3.4 批量处理
当需要处理大量图像时,EasyOCR支持批量处理模式。通过循环调用readtext方法,可以一次性处理多个图像文件:
import glob
# 获取所有图像文件路径
image_paths = glob.glob('images/*.jpg')
# 对每个图像文件进行OCR识别
for path in image_paths:
result = reader.readtext(path)
for (bbox, text, prob) in result:
print(f"文件: {path}, 识别到的文本: {text}, 置信度: {prob}")
3.5 自定义模型
对于某些特殊应用场景,EasyOCR允许用户训练自己的OCR模型。这通常涉及到收集和标注数据集、选择合适的神经网络架构以及调整超参数等步骤。虽然这部分内容较为复杂,但对于有经验的开发者来说仍然是可行的。
四、总结
EasyOCR凭借其简洁易用的API设计、丰富的功能模块以及出色的性能表现,成为Python开发者处理OCR任务的理想选择。无论是简单的单张图像识别,还是复杂的多语言混合识别和批量处理,EasyOCR都能胜任。它不仅简化了光学字符识别流程,还提供了详尽的图像预处理选项,确保最佳的识别效果。
